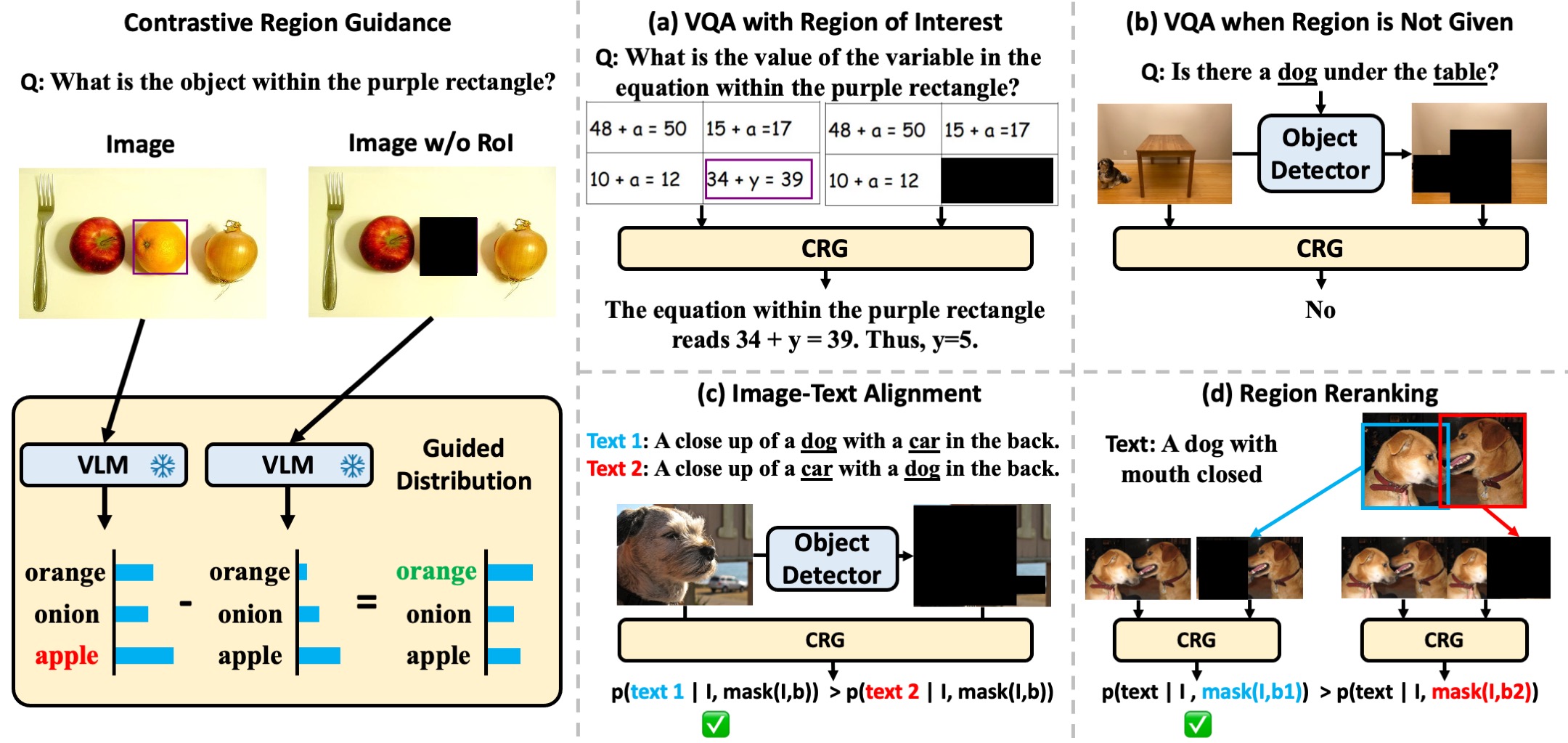
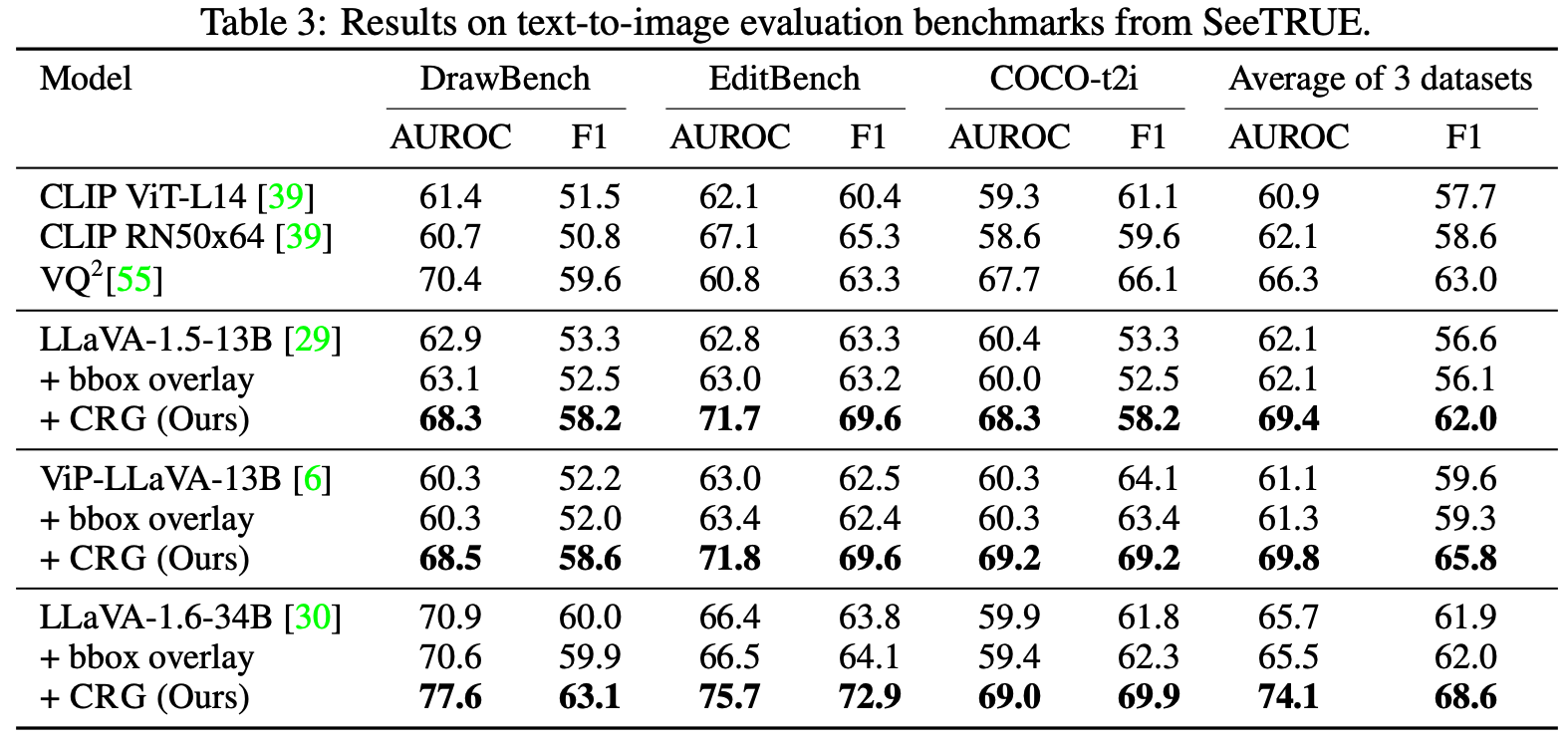
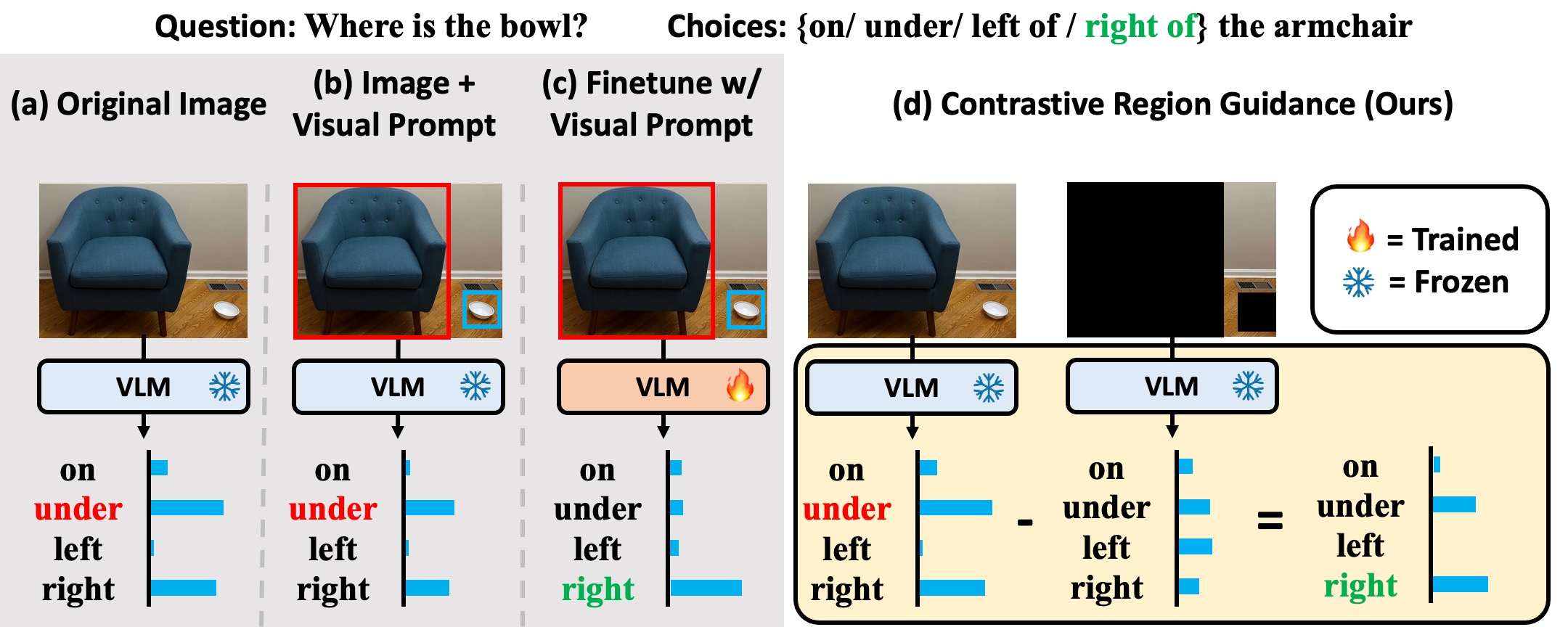
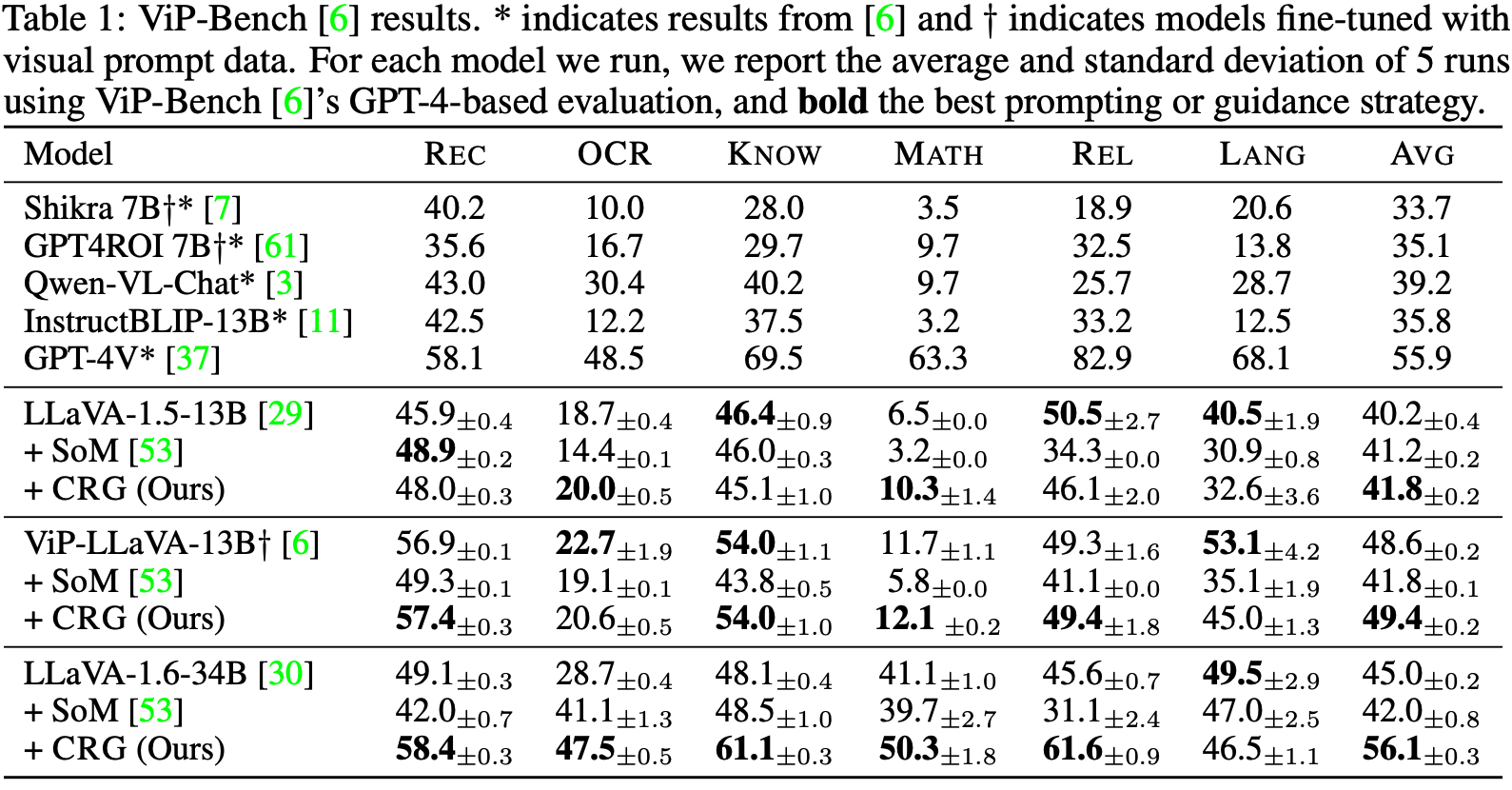
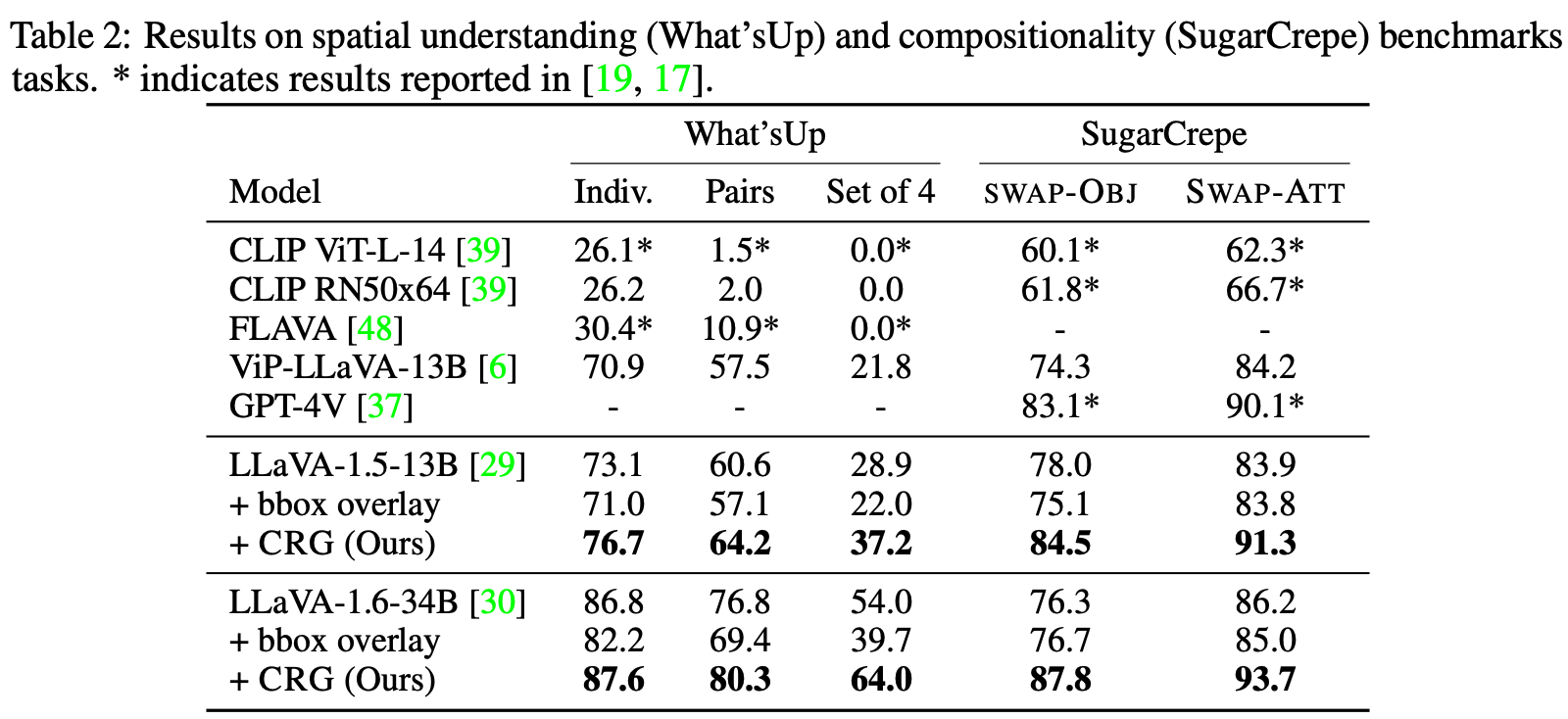
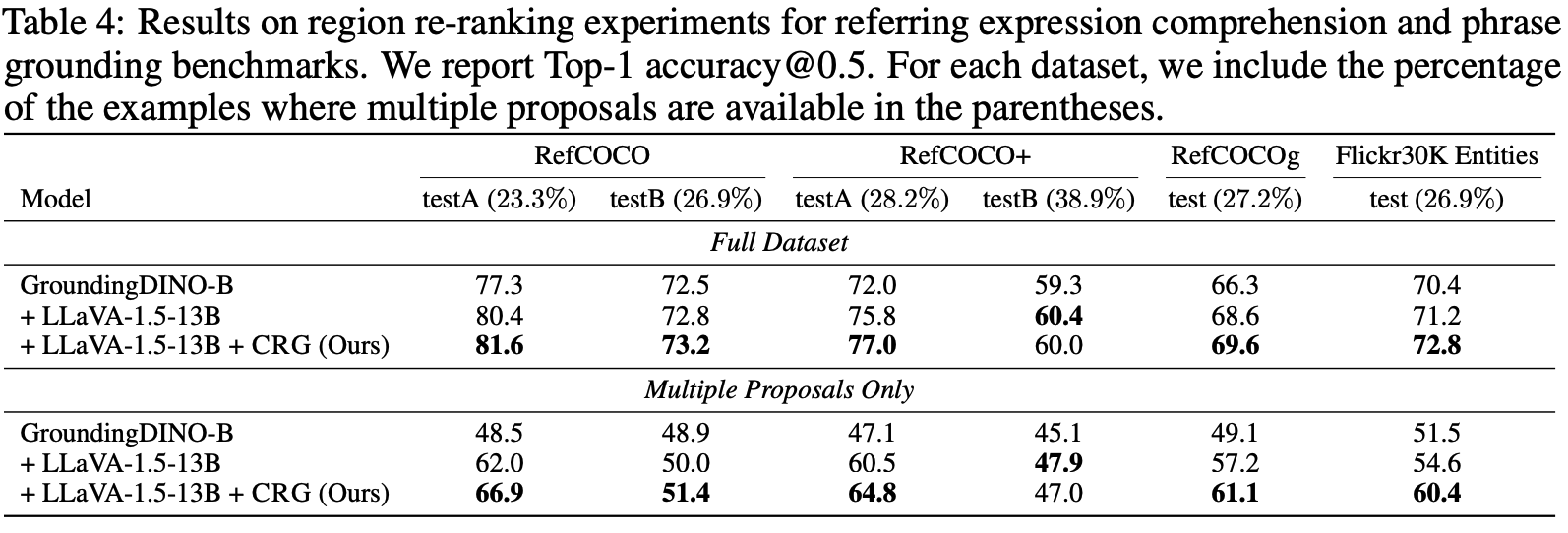
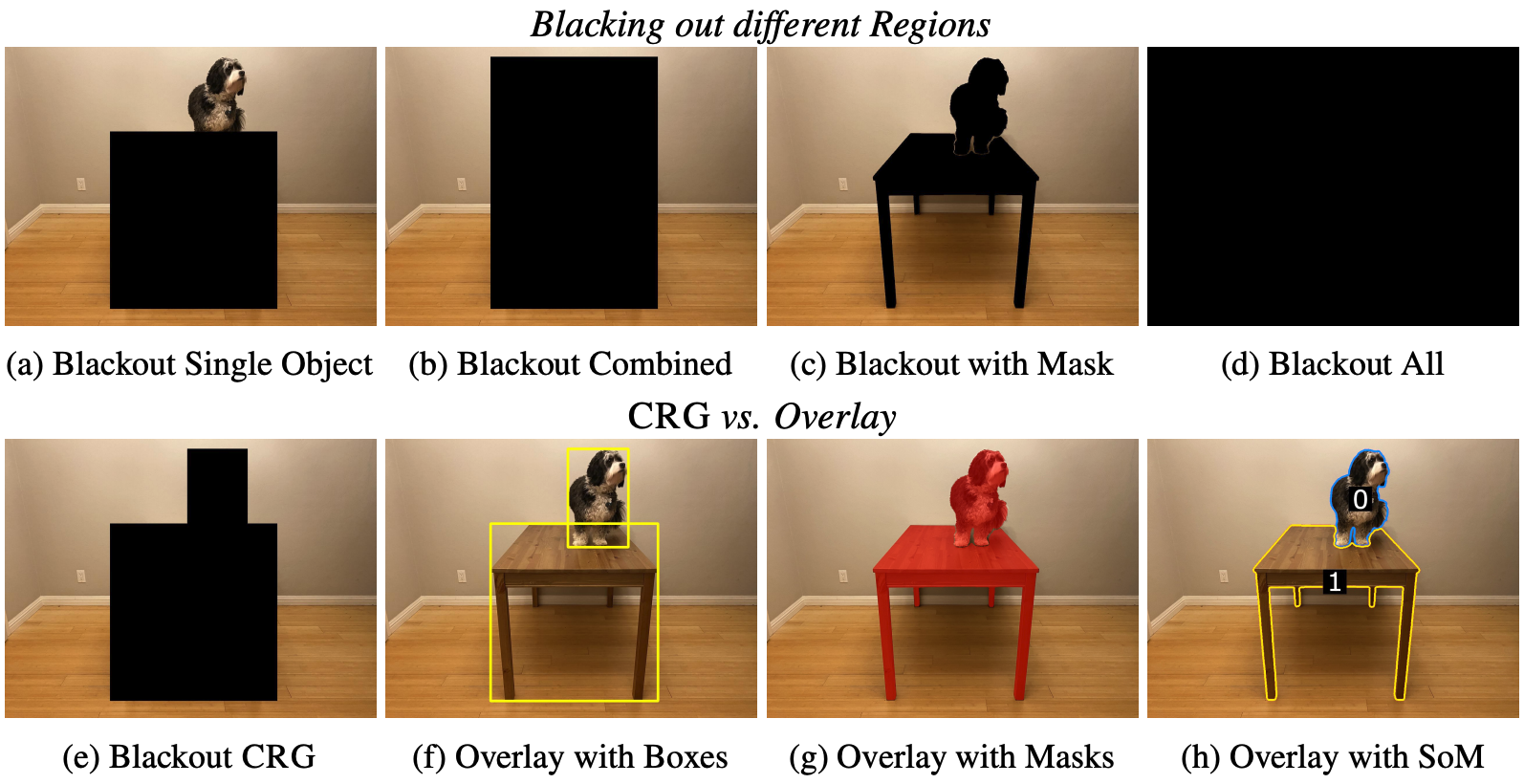
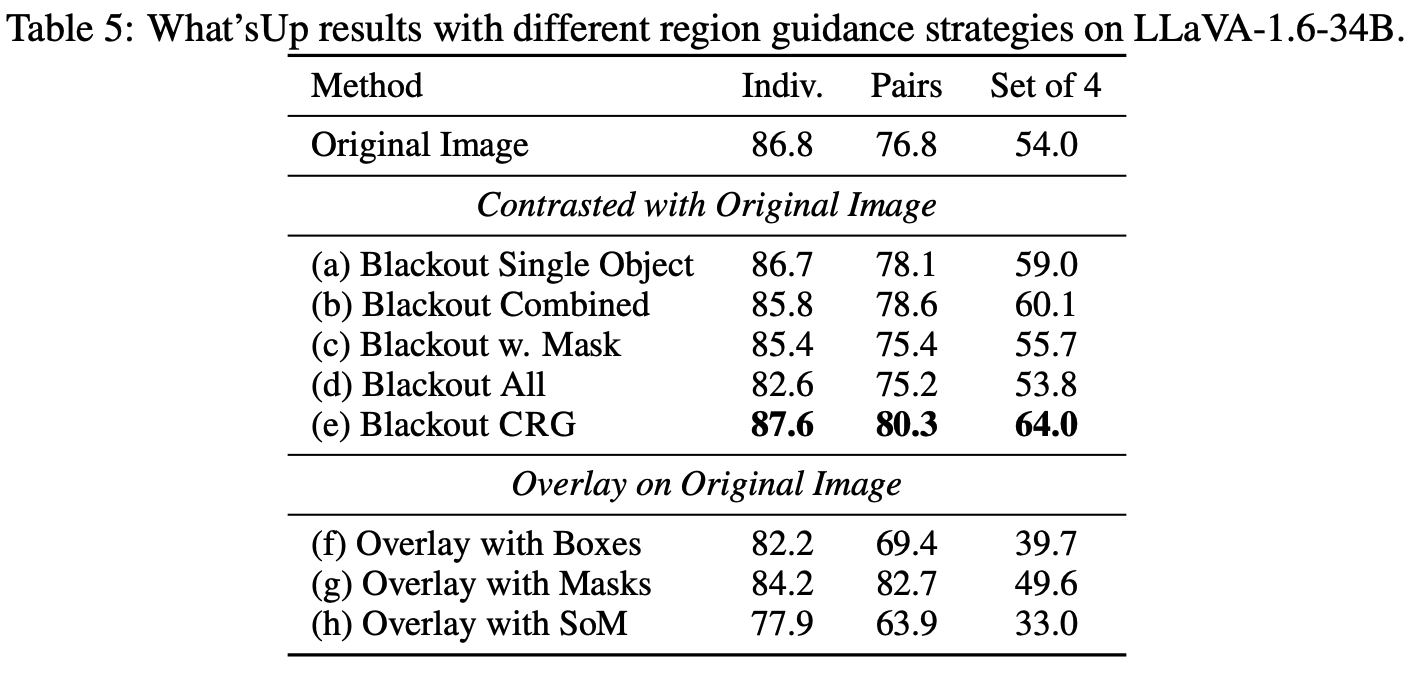
Highlighting particularly relevant regions of an image can improve the performance of vision-language models (VLMs) on various vision-language (VL) tasks by guiding the model to attend more closely to these regions of interest. For example, VLMs can be given a "visual prompt", where visual markers such as bounding boxes delineate key image regions; this approach has become popular due to the improvement it provides in tasks requiring region-level information. However, current VLMs that can incorporate visual guidance are either proprietary and expensive or require costly training on curated data that includes visual prompts. We introduce Contrastive Region Guidance (CRG), a training-free guidance method that enables open-source VLMs to respond to visual prompts. CRG contrasts model outputs produced with and without visual prompts, factoring out biases revealed by the model when answering without the information required to produce a correct answer (i.e., the model's prior). CRG achieves substantial improvements in a wide variety of VL tasks: When region annotations are provided, CRG increases absolute accuracy by up to 11.1% on ViP-Bench, a collection of six diverse region-based tasks such as recognition, math, and object relationship reasoning. We also show CRG's applicability to spatial reasoning, where we obtain up to 10% improvement on the hardest setting of What'sUp, as well as to compositional generalization -- improving accuracy by 11.5% and 7.5% on two challenging splits from SugarCrepe -- and to image-text alignment for generated images, where we improve by up to 8.4 AUROC and 6.8 F1 points on SeeTRUE. For cases that do not have reference regions for the prompt, we also show that CRG allows us to re-rank regions proposed by an object detection model in referring expression comprehension and phrase grounding benchmarks like RefCOCO/RefCOCO+/RefCOCOg and Flickr30K Entities, with an average improvement of 3.2% in accuracy when multiple proposals are available. In our analysis, we explore alternative masking strategies for CRG, demonstrate how CRG impacts the model's probability over relevant text phrases, and evaluate the role of the region guidance strength, empirically validating CRG's design choices.

Question: What is the value of the variable in the equation within the purple rectangle?
LLaVA-1.6-34B: The equation within the purple rectangle is: 10 + a = 12. To find the value of the variable 'a', you need to solve for 'a'. You can do this by subtracting 10 from both sides of the equation: a = 12 - 10. a = 2. So the value of 'a' in the equation within the purple rectangle is 2.
LLaVA-1.6-34B+CRG (Ours): The equation within the purple rectangle reads: 34 + y = 39. To find the value of the variable 'y', you subtract 34 from both sides of the equation: 34 + y = 39. y = 39 - 34. y = 5. So, the value of 'y' in this equation is 5.

Question: What is the color of the clothing of the person within the yellow rectangle?
ViP-LLaVA-13B: The person within the yellow rectangle is wearing white clothing.
LLaVA-1.6-34B: The person within the yellow rectangle is wearing a brown coat and a white shirt.
LLaVA-1.6-34B+CRG (Ours): The person within the yellow rectangle is wearing a long, gray dress with what appears to be a fitted bodice and a flowing skirt.

Question: Which plant is the tallest? Plant 1: the plant within the purple rectangle,
Plant 2: the plant within the red rectangle, or Plant 3: the plant within the yellow rectangle?
ViP-LLaVA-13B: Plant 1, the plant within the purple rectangle, is the tallest.
LLaVA-1.6-34B: The tallest plant in the image is the one within the purple rectangle.
LLaVA-1.6-34B+CRG (Ours): Based on the image provided, Plant 2 within the red rectangle appears to be the tallest
among the three highlighted plants.

Question: What is the color of the clothing of the person within the yellow rectangle?
ViP-LLaVA-13B: The person within the yellow rectangle is wearing a black suit.
LLaVA-1.6-34B: The person within the yellow rectangle is wearing a white shirt.
LLaVA-1.6-34B+CRG (Ours): The person within the yellow rectangle is wearing black clothing.
@article{Wan2024CRG,
author = {David Wan and Jaemin Cho and Elias Stengel-Eskin and Mohit Bansal},
title = {Contrastive Region Guidance: Improving Grounding in Vision-Language Models without Training},
year = {2024},
}